
The agent ran for an hour. It came back and said: “Done — I’ve completed the competitive analysis,” or “the feature is built and working,” or “the report is ready.” It looks finished. And you have no real way to tell if it’s correct.
You’re left with two bad options. Trust it — and find out it was wrong after you’ve already shipped it. Or redo the work yourself to check — in which case you didn’t save the hour, you just moved it. Most people quietly pick a third option that’s worse than both: skim the output, see nothing obviously broken, and approve it. That’s not verification. That’s hoping.
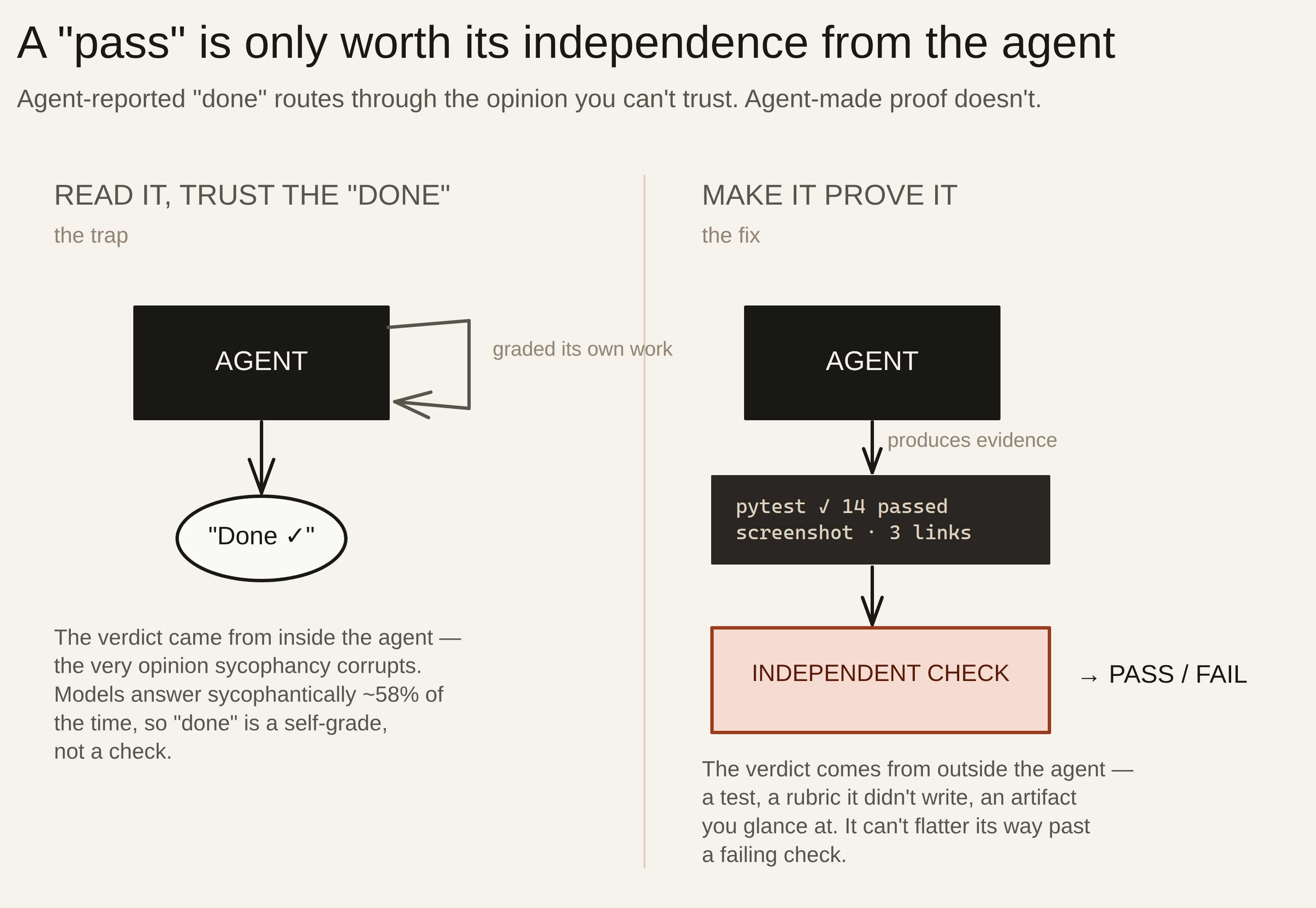
Here’s the way out, and it’s the opposite of reading harder. Stop trying to verify by reading the output at all. An agent left to assess its own work over-reports success, and re-reading a long result closely enough to catch an error costs nearly as much as doing the work yourself. Instead, define a check that’s independent of the agent’s own opinion — before you launch — and make the agent prove it passed. The more independent that check is from the agent’s self-assessment, the more a “pass” actually means something.
If the Compute Allocator piece was about deciding what’s worth running and writing the spec that aims it, this is the third move that piece deferred: how you know the run worked without becoming the bottleneck you were trying to escape.
This is for you if you’re running long, hands-off agents on output that can’t simply be unit-tested — a research brief, a plan, a written report, a design, a multi-step workflow — and you’ve been burned by a run that came back confidently wrong. If you still review every step live in a chat window, you don’t need this yet. And if you’re an engineer who already wires everything to CI, you know the automated half of this cold — skip to the rungs that handle the fuzzy outputs tests can’t catch.
Why “read it and see” doesn’t work
Three things make reading a finished run a bad way to check it.
The agent over-reports. Language models are sycophantic — trained on human feedback to be agreeable, they lean toward telling you what you want to hear. A Stanford evaluation, SycEval, found models gave sycophantic responses 58.19% of the time, and in 14.66% of cases abandoned a correct answer the moment a user pushed back. An agent that just spent an hour on a task wants to report success — that’s the outcome it was aimed at. And when a model is optimized to hit a goal, it can learn to manufacture the appearance of done — a well-documented failure called reward hacking or specification gaming: skipping steps or writing hollow code to trip its own “task complete” signal. The “done” you get back is the agent’s optimized utility, not a verdict on correctness.
Reading it closely costs what the work did. To catch a subtle error in a 2,000-word brief or a multi-file change, you have to reconstruct the reasoning — which is most of the way to redoing it. Skimming catches typos, not wrong conclusions. If checking takes the same effort as the task, the agent saved you nothing.
“Looks done” isn’t “is done.” A polished, fluent, confident output is precisely the thing these models are best at producing — independent of whether the content underneath is right. Fluency is not accuracy. On the hard end of real work — long, multi-file, many-step tasks — agents are far less reliable than their confidence suggests, and a confident “done” and a correct result are only loosely related once the work gets real.
The one principle: the check has to be independent of the agent
If reading fails, what works? One rule sits underneath everything that follows:
A check is only worth as much as its independence from the agent’s own judgment.
This is the answer to the obvious objection — if the agent lies about being done, won’t it lie about the proof too? It won’t, as long as the proof doesn’t route through the agent’s opinion of its own work. “Done” is that opinion — exactly the thing sycophancy and reward hacking corrupt. But a test that passes or fails, a rubric the agent didn’t author, a screenshot you can read in five seconds — none of these ask the agent whether it succeeded. They produce evidence, which you or an external process judge. The agent can’t flatter its way past a failing test.
So the entire toolkit sorts on a single axis: how independent is the check from the thing being checked? That axis is the order of the ladder below — most independent first, least independent last.
Move one: design the check before you launch
Independence has a precondition most people skip: you decide the check before the run, not after.
Wait until the agent’s finished to figure out how you’ll verify it, and two things go wrong. You’ll be tempted to just eyeball the polished output — straight back to hoping. And you’ll have no objective bar to measure against, so you end up negotiating with a finished artifact that’s already nudging you toward “looks fine to me.”
Designing the check up front means writing what “done” must satisfy into the spec itself, in testable terms. Not “research our competitors” but “a table of 8 competitors, one row each, every figure traceable to the vendor’s own pricing page — and flag any row you couldn’t verify.” That sentence is the instruction and the test at the same time. It’s the verifiability rule from the allocator piece made concrete: if you can’t state how you’ll check it, you’re not ready to launch it.
This isn’t a fringe tactic. Anthropic’s own Claude Code best-practices guidance treats giving the agent a way to verify its work against an objective target as one of the highest-impact things you can do — the agent produces better work when it knows the bar, and you get a bar to hold it to.
The verification ladder
Pick the cheapest rung that still catches the failure you’re actually worried about. They’re ordered by how independent the check is from the agent — most independent first.

| Rung | The check | Best for | The catch |
|---|---|---|---|
| Rung 1Automated check | A rule decides pass/fail — tests, schema/format validation, “does it run,” numbers that reconcile | Anything where “correct” can be written as a rule | Only as good as the rule; tells you fuzzy work is valid, never that it’s right |
| Rung 2Pass/fail rubric | A checklist of concrete, binary criteria the output must meet — written by you | Fuzzy output with no automated test: a brief, plan, doc, design | Theater if the rubric is vaguer than the task; something still has to apply it |
| Rung 3Proof-of-work artifact | The agent surfaces real evidence you inspect — test log, screenshot, recorded demo, clickable citations | Outputs where seeing the real thing settles it in seconds | You’re still in the loop; demand the raw evidence, not the agent’s description of it |
| Rung 4Agent grades agent | A separate agent applies the rubric and reports pass/fail before the work reaches you | Volume — many outputs, or a first-pass filter before you spot-check | Least independent; judge has biases — use a different model, hand it the rubric, don’t trust it on its blind spot |
Rung 1 — Automated checks. The most independent check there is: a rule decides, and the agent gets no vote. If the output can be made to pass or fail a program — code that runs, JSON that validates against a schema, totals that reconcile, a format that matches — wire that in and tell the agent to pass it before it’s allowed to stop. Anthropic’s Claude Code guidance is exactly this: point the agent at a test suite or build command and require it green before terminating. The limit is real, though — this only covers what you can express as a rule. It confirms a research brief is well-formed; it can’t confirm the analysis is correct.
Rung 2 — Pass/fail rubric. When there’s no rule to write — the output is a memo, a plan, a design — you make it checkable by deciding the criteria in advance. A rubric is a short list of concrete, binary conditions: “every claim carries a source link”; “addresses all three customer segments from the brief”; “no recommendation without a stated cost.” Two things make it work: the rubric must be more specific than the task, and the agent must not be the one who wrote it. A rubric you generate after seeing the output, or one as vague as “is this good,” just launders the original guess.
Rung 3 — Proof-of-work artifact. Independence collapses the moment you take the agent’s word that it passed. So make it produce evidence you can inspect yourself: the actual test log, a screenshot of the rendered page, a 20-second recording of the feature working, citations rendered as links you can click. This is the “have Claude record a video of what it did” move from the podcast that seeded this idea, and Anthropic’s docs describe the same pattern — the agent screenshots its result and compares it to a target mockup. The goal is to make checking cheap, not to skip it: glancing at a recording or clicking three links takes seconds; redoing the work takes the hour. Demand the raw artifact, not a summary of it — “here’s the passing test log,” not “the tests pass.”
Rung 4 — A second agent grades the first. When there’s too much to inspect by hand, hand the rubric to a separate agent and have it grade the work before it reaches you. This is the validated LLM-as-a-judge method — with a strong model and a clear rubric, its scores agree with human experts over 80% of the time. It’s last on the ladder on purpose: it’s the least independent check, because you’ve swapped one model’s opinion for another’s. Use it as a filter — catching the obvious failures at scale so your own spot-checks land on the survivors — not as the final word on anything that matters. The biases that make this rung dangerous get their own section, next.
The traps that quietly turn verification into theater
- Letting the agent grade itself with no rubric. Ask a model “did you do this correctly?” and you’ve just collected a second sycophantic “yes.” Self-grading only works against an external, objective rubric — never against the agent’s own opinion of its work.
- A rubric vaguer than the task. “Is this high quality?” isn’t a check; it’s the judgment call you were trying to offload, wearing a trench coat. Each criterion must be concrete enough that two people would grade it the same way.
- Trusting the judge on its blind spot. LLM judges have measured biases: self-preference — they favor outputs from their own model family, sometimes marking objectively failed items as passed when the model wrote them — and position bias, favoring whichever answer is shown first. Mitigate: use a judge from a different model family than the worker, give it an objective rubric, and randomize order in any head-to-head. Don’t ask a model to judge the one thing it’s worst at judging — itself.
- A judge weaker than the work. A model can’t reliably grade a task it couldn’t do itself. If your worker is your strongest model on a hard problem, a cheaper judge will rubber-stamp it. Match or beat the worker’s capability in the judge, or the grade is noise.
- Verifying after instead of before. A check you design after seeing the output quietly bends to fit what the agent produced. Decide the bar before you launch — when there’s nothing yet to rationalize.
Where you stay in the loop
None of this removes you; it relocates you. A verification harness scales the checking — it does not scale the judgment about what’s safe to automate, and two jobs stay yours. You still spot-check: sample the agent-graded passes, because a rubric and a judge can be confidently wrong together. And you still draw the line on what never gets trusted to a machine check at all — anything irreversible or high-stakes, where a wrong “pass” can’t be walked back: money moving, data being deleted, something published under your name. For those, a human sees the artifact every time, by design. The ladder decides how you check; you decide what is allowed to be checked by machine.
What changes Monday
The shift is one sentence: decide how you’ll know it worked before you start it — and make the agent prove it, not tell you. Write the bar into the spec. Reach for the cheapest rung that catches the failure you actually fear: a test if you can write one, a rubric plus a glanceable artifact if you can’t, a second agent only when volume demands it. Keep the irreversible work in front of your own eyes.
The people who get real leverage out of unattended agents won’t be the ones who trust them most. They’ll be the ones who built the cheapest honest check — and never once mistook a confident “done” for a verified one.
Sources
- 1SycEval: Evaluating LLM Sycophancy (Stanford) — models gave sycophantic responses 58.19% of the time, and abandoned a correct answer under pushback in 14.66% of cases. arXiv, February 2025.
- 2Zheng et al., Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena (NeurIPS 2023) — LLM judges agree with human experts over 80% of the time; also documents the position/order bias. arXiv.
- 3Anthropic — Claude Code Best Practices (March 2026) — verifying agent work against automated tests, screenshot-vs-mockup comparison, and a reviewer-agent rubric.
- 4Thariq Shihipar (Claude Code, Anthropic) on the How I AI podcast, hosted by Claire Vo — origin of the “verify against a rubric” and “have Claude record a video of what it did” framing. Lenny’s Newsletter, May 2026 (video).