
You can now hand a single task to an AI agent and walk away. It runs for hours — sometimes the better part of a day — with no one watching. In its own testing, Anthropic’s Claude Sonnet 4.5 ran for roughly 30 hours straight to build an 11,000-line Slack clone. That isn’t a chatbot waiting on your next message. It’s a worker you start and leave alone.
Which raises the question you came here with: if the agent does the work, what is your job?
Here’s the answer. You stop being the operator — the person who does the task keystroke by keystroke — and become the compute allocator: the person who decides which tasks are worth an expensive, unattended run, and who writes the brief that aligns the agent before it spends. Execution is no longer where you add value. The decision and the spec are.
This is for you if you’re already kicking off long, hands-off agent runs — coding agents, deep-research jobs, multi-step workflows — and you’ve felt the sting of one that churned for an hour and came back wrong. If you’re still using AI as a chat box or a faster autocomplete, this won’t apply to you yet. Come back when you do.
Why this is suddenly your problem
Two things changed at once: agents got long, and runs got metered.
They got long. The research group METR tracks a “time horizon” — the length of task a model can reliably finish without a human stepping in — and it’s been doubling roughly every seven months. That curve is what turns a chat assistant into something you can start and leave: minutes became hours, and hours are becoming days.
They got metered. Unlike a flat monthly tool, an autonomous agent bills by the token, and it pays that bill on every turn. Each loop re-reads the growing pile of instructions, files, and prior output before it does anything new — so cost climbs faster than the work does. An agent that gets stuck in a reasoning loop, keeps retrying a failing step, or wanders down a dead end can burn through a lot of money before it surfaces. A single complex run can run into the hundreds of dollars.
Put those together and the math flips.
When the work was instant and free, a vague brief cost a few wasted seconds and a retry. Now it can burn a long, metered, unattended run — and you don’t find out until it comes back wrong.
The cost of being unclear moved from trivial to real. That’s why the clarity you bring up front is suddenly the expensive part.
What a compute allocator actually does
The job isn’t gone. It moved — from the keyboard to the decision before the keyboard.
An operator sits in the loop and produces the work: typing, clicking, correcting as they go. A compute allocator sits above the loop and produces three things instead — a decision (is this worth a run?), a spec (what exactly should the run produce?), and a success check (how will I know it worked without re-doing it myself?). The agent supplies the labor. You supply the judgment that keeps the labor pointed at the right target.
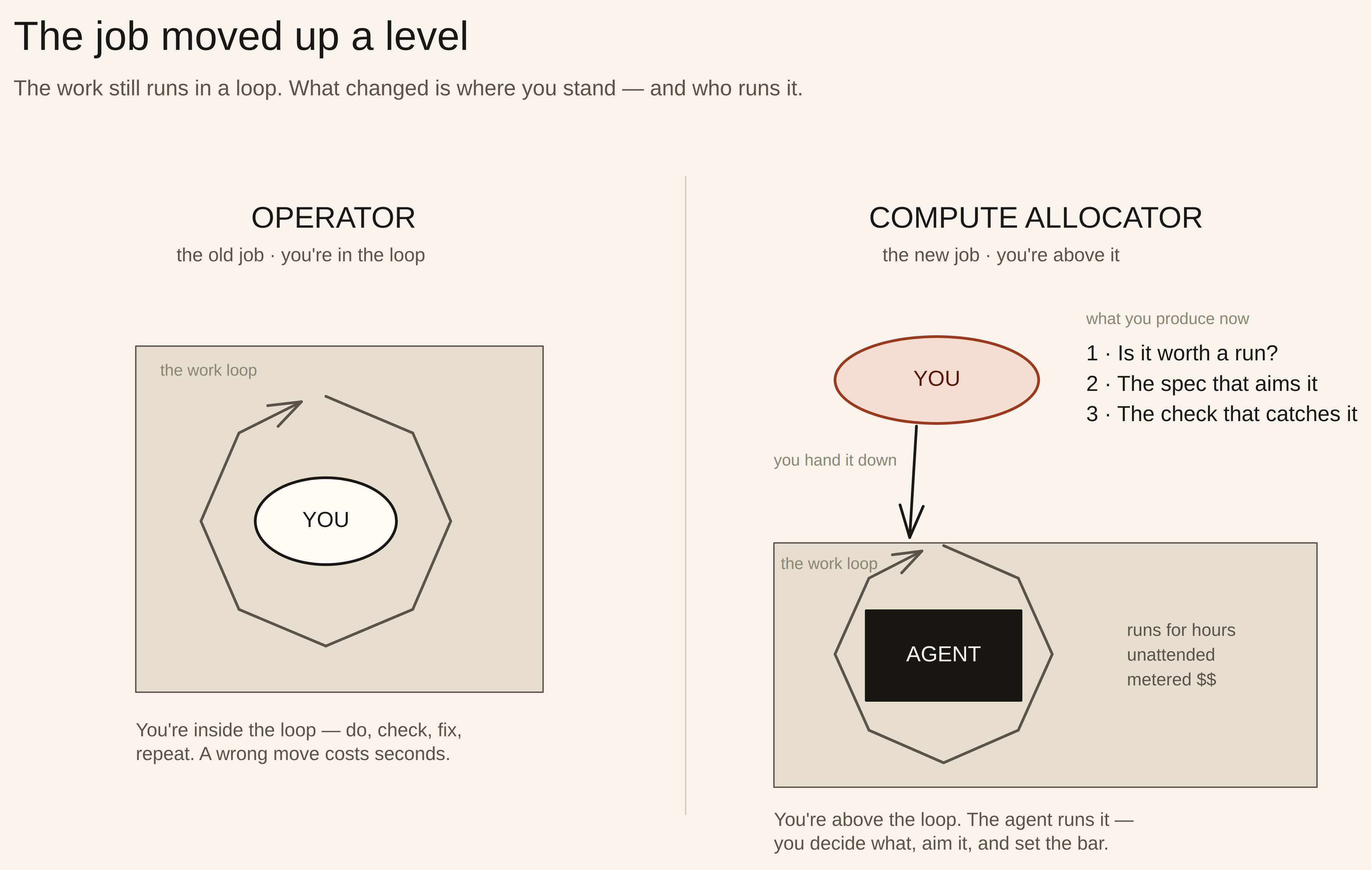
| Operator old job | Compute allocator new job | |
|---|---|---|
| Where your time goes | Doing the task | Deciding which tasks are worth a run |
| Main output | The work itself | The brief that aligns the agent |
| When you add value | During execution | Before execution — and at the check after |
| What a mistake costs | A redo | A wasted metered run |
| Skill that compounds | Doing it faster | Specifying it more clearly |
None of this requires you to be an engineer. It requires you to get good at two things most knowledge workers have never had to do deliberately: deciding what’s worth running, and writing a brief precise enough that an unsupervised worker can’t drift. That’s the rest of this piece.
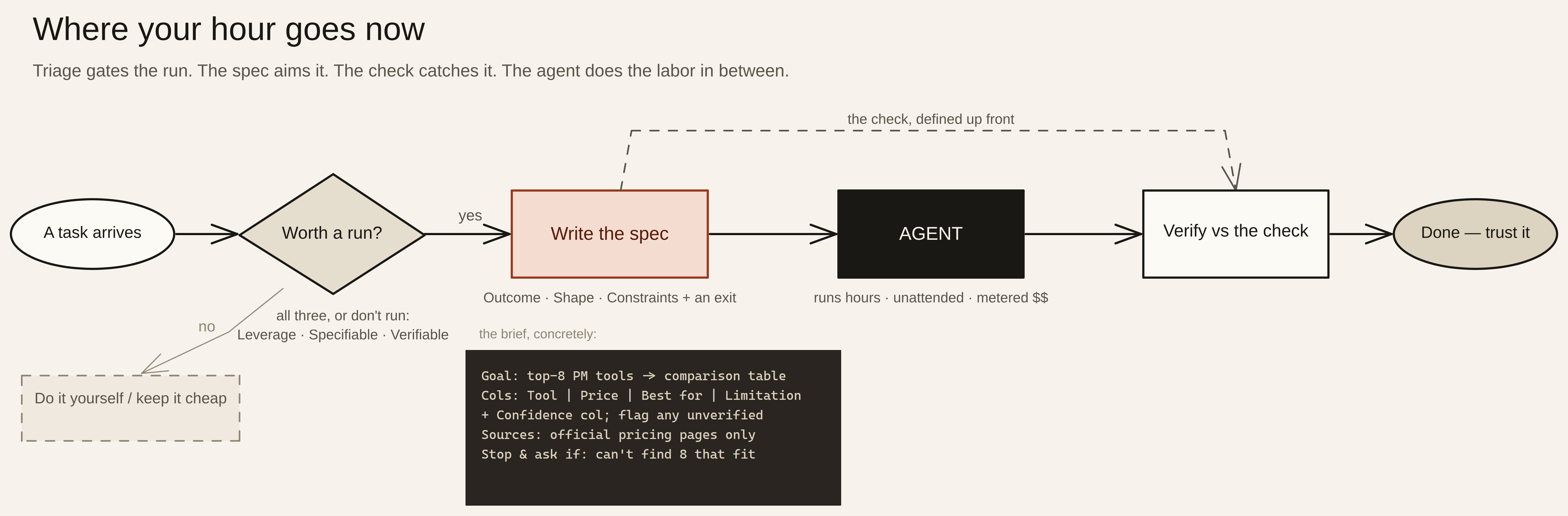
Triage: which tasks are even worth a run
Before you launch anything, run it through three quick tests. A task earns a long, unattended run only if it passes all three:
- Leverage — is it big enough to be worth it? If you could finish it yourself in ten minutes, just do it. Unattended runs earn their cost on work that’s large, repetitive, or would eat an afternoon — not on things you’re delegating out of mild reluctance.
- Specifiability — can you describe “done”? If you can’t write down what a finished result looks like, the agent can’t hit it, and you’ve bought an expensive guess. Can’t specify it yet? That’s the signal to either think harder or keep the task in a cheap, interactive back-and-forth where you correct as you go.
- Verifiability — can you check it without redoing it? If the only way to know the run worked is to do the whole thing yourself and compare, you’ve saved nothing. You need a cheap way to confirm success — a test, a spot-check, a rule the output must satisfy.
A useful way to hold it: fail “specifiability,” fix the brief first; fail “verifiability,” build the check first; fail “leverage,” just do the task yourself. The expensive run is the last resort, not the first reflex.
Write the spec that aligns the agent before it spends
This is the highest-leverage hour you have, so spend it deliberately. A brief that keeps an unsupervised worker on target has three parts:
- The outcome — what “done” looks like, concretely. Not “research our competitors” but “a table of our top eight competitors, one row each, with columns for pricing, target customer, and main weakness — and flag any row you couldn’t verify.” The agent optimizes for whatever you actually wrote, so write the finish line, not the topic.
- The shape of the output. State the format and structure up front — the columns, the file type, the sections, the length. Defining the shape of the result is the difference between getting back something you can use and something you have to reformat. This is the boundary that lets you delegate the how without being surprised by the what.
- The hard constraints — and an exit. Name what it must not do and where the edges are: which sources to trust or avoid, what’s out of scope, how long to spend. Then give it an explicit out — “if a step is ambiguous or you’re missing what you need, stop and ask rather than guessing.” An agent told to stop when stuck wastes far less than one told to power through.
A tight brief might read:
Goal: A comparison table of the top 8 project-management tools for small agencies.
Output: Markdown table. Columns: Tool | Price/user/mo | Best for | Biggest limitation.
One row per tool. Add a "Confidence" column; mark any figure you couldn't
confirm from the vendor's own site as "unverified."
Constraints: Use official pricing pages only — no listicles or affiliate roundups.
If a vendor hides pricing, write "contact sales," don't estimate.
Stop and ask if: you can't find 8 tools that genuinely fit small agencies.Notice what that brief does: it pins the outcome, fixes the shape, sets the constraints, and gives the agent an out. Five minutes of writing that spec saves you a metered run that comes back as an unsourced wall of marketing copy.
Then decide how you’ll know it worked
One more move, and it belongs in the brief: define the success check before you launch, not after.
Agents tend to over-report success — left to grade themselves, they’ll tell you it’s done. So hand them an objective bar instead. The pattern is well established in agentic tools: Anthropic’s Claude Code best-practices describe wiring runs to automated tests, having the agent screenshot a result and compare it to a target, or spawning a separate reviewer agent to check the work against an explicit rubric before it reaches you. The general version for any task: decide the one or two conditions a result must meet, and make confirming them cheaper than redoing the work. (How to build verification harnesses well is a topic of its own — worth its own piece.)
What changes Monday
The shift is small to describe and large in effect: spend your first hour on the brief, not the build. Triage what’s worth a run, write the spec that aims it, and decide how you’ll check the result — then let the agent do the labor.
The people who get the most out of autonomous agents won’t be the ones who type fastest. They’ll be the ones who decide most clearly what’s worth running and describe it most precisely.
In a world where the work runs itself, clarity is the job.
Sources
- 1Thariq Shihipar (Claude Code, Anthropic) on the How I AI podcast, hosted by Claire Vo — origin of the “compute allocator” framing and the spec-as-leverage argument. Lenny’s Newsletter, May 2026 (video).
- 2Addy Osmani — Long-running Agents (April 2026) — on METR’s “time horizon” doubling roughly every seven months and the rise of reliable unattended run length.
- 3Slashdot — Claude Sonnet 4.5’s ~30-hour autonomous run building an 11,000-line Slack clone (September 2025).
- 4Anthropic — Claude Code Best Practices (March 2026) — agentic verification against tests, screenshots, and reviewer-agent rubrics.