

On June 9, Anthropic shipped Claude Fable 5 and called it the most powerful model it has ever made generally available — state of the art on nearly every benchmark it published, with a special lead on hard, long-horizon coding and science work (Anthropic). The headlines wrote themselves, your feed filled with “most powerful model ever,” and a lot of people did the obvious thing: they switched their default to Fable 5 and started running everything through it.
That’s the mistake this piece is about. Fable 5 is real, and the benchmarks are not marketing fluff. But “most powerful” is not the same as “right for what you’re doing,” and Fable 5 is priced, gated, and tuned in ways that make it the wrong default for the everyday work most of us actually do. It’s a specialist tool wearing a generalist’s launch.
This is for you if you build real things with Claude — in Claude Code, the API, or the apps — and you felt the pull to upgrade everything the moment Fable 5 dropped. It is not for frontier-benchmark researchers (you already read the model card), and it is not for people who don’t pay for AI at all. Here are seven things worth knowing before you spend a dollar on it — and the one case where spending it is exactly right.
Seven things to know before you switch
1. It’s real — and the most powerful model Anthropic has ever put in public hands
Take the hype seriously, because for once it’s earned. Fable 5 is state of the art on nearly every benchmark Anthropic tested — software engineering, knowledge work, vision, scientific research — and it shipped on June 9, 2026 across the Claude API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry (Anthropic; Amazon). On some benchmarks it scores more than 10% above Claude Opus 4.8, the model Anthropic released only weeks earlier (CNBC). What it means for you: don’t dismiss this as a numbered point release — the capability jump is genuine, and on the right task you’ll feel it. The rest of this list is about making sure you only pay for it on those tasks.
2. “Fable” is “Mythos” wearing a seatbelt
Anthropic shipped two models that day: Claude Fable 5 and Claude Mythos 5. They are the same underlying model. Mythos 5 is the unrestricted version — it has the strongest cybersecurity capabilities of any model in the world and is not generally available; access is limited to vetted customers through a program Anthropic calls Project Glasswing (Anthropic). Fable 5 is that same model with safeguards added so it’s safe to hand to the public (9to5Google).
So the name decodes cleanly: Mythos is the dangerous, gated frontier; Fable is the version told as a bedtime story — same plot, safety rails on. And the takeaway is the inverse of how people read it: you are not getting a watered-down model. You’re getting the frontier model with guardrails. What it means for you: stop thinking of Fable 5 as “a bigger Opus.” Think of it as “Mythos, minus the parts Anthropic won’t let the public touch” — which makes the next point obvious.
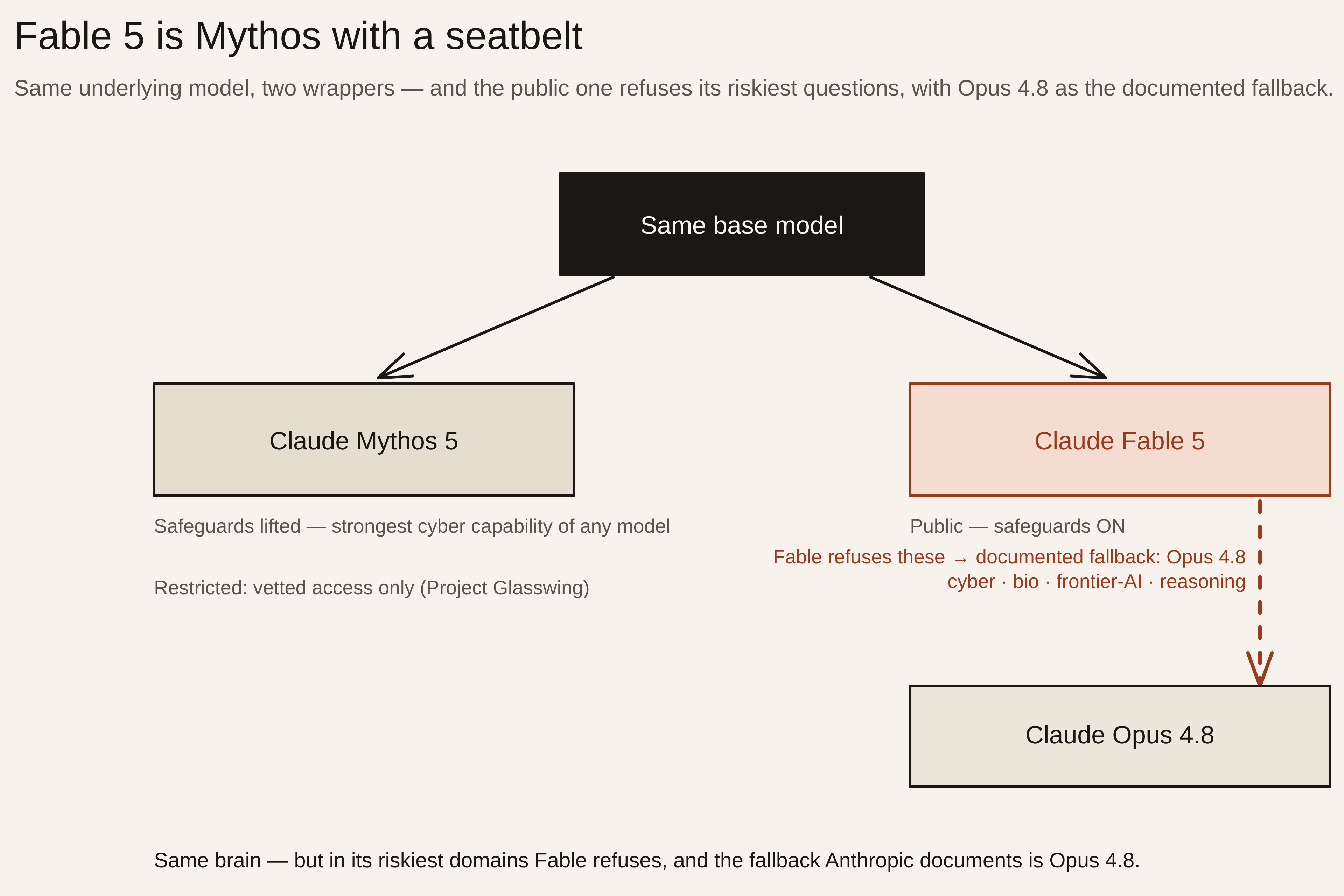
3. In its highest-stakes domains, it refuses — and the fallback Anthropic hands you is Opus 4.8
The safeguards aren’t a content filter that scolds you. They’re a refusal layer. Ask Fable 5 something its classifiers flag as high-risk — Anthropic’s four categories are cybersecurity, biology, frontier-AI development, and extracting the model’s own hidden reasoning — and instead of answering, it simply refuses: a normal, successful response that declines and is tagged with the category (Anthropic — Refusals and fallback). It does not silently swap in another model. What Anthropic documents instead is that you wire up a fallback — and the example they hand you is Claude Opus 4.8. There’s a second wrinkle, too: early users report Fable 5 over-refusing perfectly innocuous prompts, presumably because the new safeguards are tuned conservatively at launch (The Register). What it means for you: in exactly the domains where you’d most want the extra muscle, Fable 5 gives you a refusal — and the path Anthropic points you to is Opus 4.8. You’re paying a 2× premium for work the model won’t do, where the safe answer comes from the cheaper model anyway. Send that work to Opus 4.8 yourself.
4. It costs exactly double Opus 4.8
Fable 5 is $10 per million input tokens and $50 per million output tokens. Opus 4.8 is $5 and $25. That’s not “a bit more” — it’s a clean 2× on every token, in and out, which makes Fable 5 the most expensive generally available frontier model Anthropic ships, and about double GPT-5.5’s input price too (Finout; OpenRouter). The discounts that make it survivable are the usual two: prompt caching gives 90% off cached reads (about $1 per million), and batch processing halves both numbers to $5/$25. Neither changes the headline math: every token you send Fable is a 2× decision against the model you were perfectly happy with last month. What it means for you: treat Fable like the premium line item it is. If a task doesn’t obviously need it, that’s your answer — the same way you don’t reach for your strongest model on trivial edits.
Every token you send Fable 5 is a 2× decision against the model you were perfectly happy with last month.
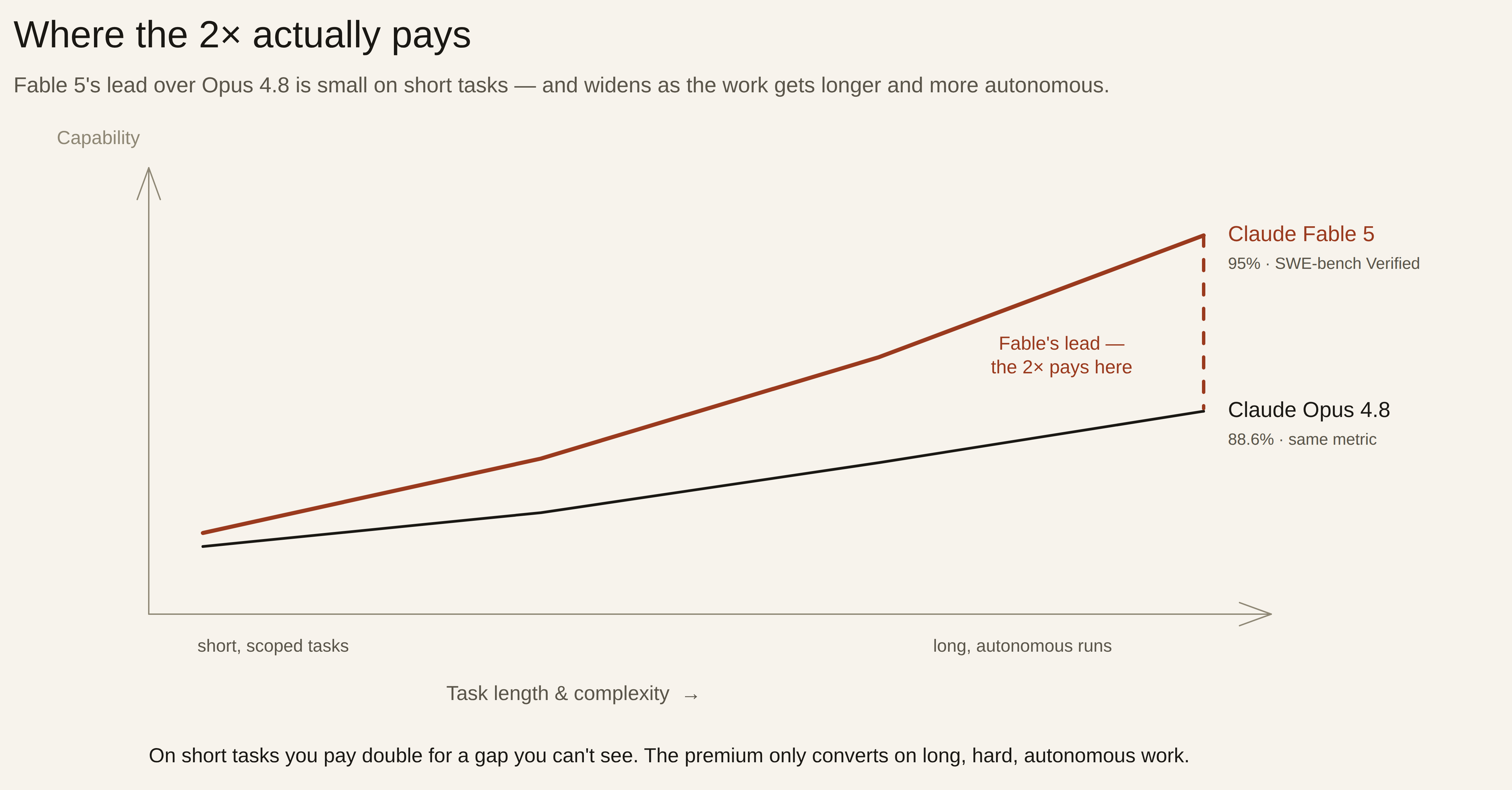
5. The 2× only buys you something on long, hard, autonomous work
This is the point that should decide it for most people. Fable 5’s lead over Opus 4.8 is real but uneven, and it concentrates almost entirely in long-horizon, complex tasks. On SWE-bench Verified it scores about 95.0% to Opus’s 88.6%; on the harder SWE-bench Pro the gap widens to roughly 80% versus 69%; on the most punishing long-context coding benchmarks it roughly doubles Opus’s score (TrueFoundry; AY Automate). The pattern every reviewer landed on: the longer and more complex the task, the larger Fable 5’s lead — and on short, well-scoped tasks the two are close enough that you won’t tell them apart. What it means for you: for a scoped code change, a summary, a draft, a quick question, you’d be paying double for a difference you can’t perceive. Opus 4.8 gives you the same answer at half the price.
6. The free ride ends June 23 — then the meter starts
Right now Fable 5 feels free: if you pay for Claude Pro, Max, Team, or seat-based Enterprise, you get it at no extra cost. That’s a launch promotion, and it has a date on it. The access runs from June 9 through June 22; on June 23, Anthropic removes Fable 5 from those plan limits, and continued use switches to usage credits billed at full API rates (CNBC; MindStudio). It’s a classic on-ramp, and it works precisely because two free weeks is long enough to build a habit. What it means for you: use the free window as a test, not a honeymoon. Take two or three real tasks where you suspect Fable might pull ahead — a big agentic refactor, a long research synthesis — and run them on both models side by side. By June 23 you’ll know whether Fable earns its premium for your work, instead of discovering the bill after the habit’s formed.
7. When it’s genuinely worth it — and what it can actually do
None of this makes Fable 5 a trap to avoid. It makes it a specialist. And on its specialty, what it can do is the genuinely impressive part: clearing 95% of SWE-bench Verified, sustaining quality across long autonomous coding runs where Opus starts to drift, and posting real gains on scientific and knowledge work (Anthropic; The Decoder). When a task is long, complex, runs with little supervision, and is expensive to get wrong, Fable’s edge stops being a benchmark decimal and becomes the difference between a run that finishes clean and one you have to babysit. What it means for you: make Opus 4.8 your default and promote to Fable 5 deliberately — for the multi-hour agentic build, the gnarly migration, the research job where a subtle mistake costs more than the tokens. Reach for it when being right is worth double. For everything else, the cheaper model was already enough.
The one to remember
Fable 5 earns its headline — it’s Mythos with the safety on, it tops the charts, and on a long, hard, autonomous job it’s the best tool you can buy. But it costs double, it simply refuses the riskiest questions (and points you to Opus for them), and its lead all but vanishes on the short tasks that make up most of your day.
“Most powerful model ever” is a fact about a benchmark, not a recommendation about your workflow.
So don’t switch your default. Keep Opus 4.8 as the model you reach for without thinking, learn — during the free window, before June 23 — exactly which of your tasks Fable actually wins, and pay the premium only there. The new shiny object is real. Reaching for it by reflex is the part you can’t afford.
Sources
- 1Anthropic — Claude Fable 5 and Claude Mythos 5 (June 9, 2026) — launch, capabilities, the Mythos relationship, and the safeguards.
- 2CNBC — Mythos-class model released to the public; more than 10% above Opus 4.8 on some benchmarks; double the price; free through June 23.
- 3Anthropic — Refusals and fallback — the refusal categories (cyber, bio, frontier_llm, reasoning_extraction) and the developer-configured Opus 4.8 fallback; Fable refuses high-risk requests rather than auto-routing them.
- 4TrueFoundry — benchmarks vs Opus 4.8 (SWE-bench Verified 95.0 vs 88.6, SWE-bench Pro ~80 vs ~69); “the longer and more complex the task, the larger Fable 5’s lead.”
- 5AY Automate — benchmark and pricing comparison; Opus 4.8 the better everyday default.
- 6Finout — API pricing $10/$50; 90% prompt-caching discount; batch halves to $5/$25; most expensive GA frontier model.
- 7MindStudio — free on Pro/Max/Team/Enterprise June 9 through June 22; usage credits at API rates afterward.
- 8The Decoder — major gains in coding and science.
- 9The Register — reports of Fable 5 over-refusing innocuous prompts at launch.
- 10Amazon — Claude Fable 5 available on Amazon Bedrock.