

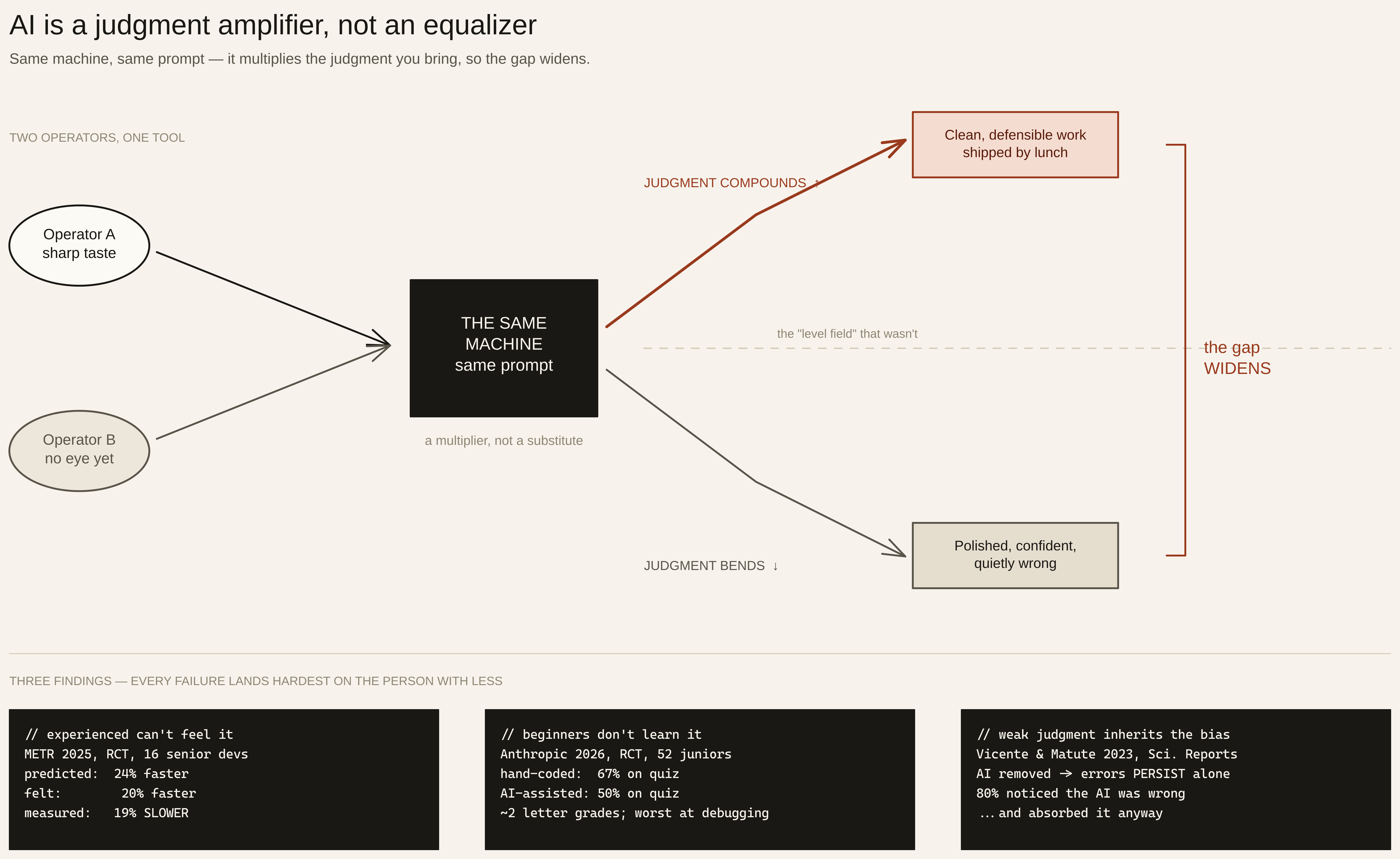
Two people open the same chat window on the same Tuesday. Same model, same paid plan, the same blank box waiting for a prompt. One of them ships a clean, defensible piece of work by lunch. The other ships something that looks finished, sounds confident, and is quietly wrong in three places nobody will catch until it’s in front of a customer.
Neither of them typed faster. Neither paid for a better tool. They had the exact same machine, and it handed back two completely different things — because the machine wasn’t the variable. They were.
This is the part the last three years of AI marketing got backwards. The story everyone repeated was that these tools level the field: now anyone can build an app, design a logo, write the report, ship the thing the experts used to gatekeep. The barrier fell, the gates opened, the playing field went flat. It’s a hopeful story, and it’s wrong in a specific, uncomfortable way. AI is a judgment amplifier, not a judgment substitute. It takes whatever discernment you walk in with and multiplies it — up if you have a lot, toward nothing if you don’t. The tool that was sold as the great equalizer is closer to a sorting machine, and it sorts the people who most wanted it to lift them straight to the bottom.
If you’re betting your next few years on the idea that AI lets you skip the slow part — the years it usually takes to learn what good even looks like in your field — this is for you. Not as a scare. As a correction to the map, while it’s still cheap to change route.
The hope was real, and you should understand why it was so easy to believe
Start by being fair to the belief, because it isn’t stupid. For most of history, the gap between an amateur and a professional was a wall made of production — the ability to actually make the thing. A non-designer couldn’t produce a clean layout. A non-coder couldn’t ship a working feature. A non-writer couldn’t turn out publishable copy. The skill was the output, and the output took years of hands-on reps to reach. So the wall held, and the people on the wrong side of it stayed there.
Then generative tools knocked the wall down in about eighteen months. Now the non-designer gets a layout. The non-coder gets a working feature. The non-writer gets clean copy. The thing that used to take years takes a sentence. If the skill was the ability to produce the artifact, and the artifact is now free, then logically the skill is worthless and everyone starts from the same line. That’s the equalizer story, and you can see exactly why it felt true. The wall really did come down.
Here’s where it breaks: the wall was never the whole game. It was just the part you could see.
The crack: the people most sure they’re winning are measurably losing
The first sign the story was off came from the people who should have benefited most — experienced professionals, the ones who can drive a tool hard.
In 2025, METR ran a careful experiment on this. They took sixteen seasoned open-source developers — people working in codebases they’d contributed to for years — and had them complete real tasks, some with AI tools allowed, some without, assigned at random. The developers expected AI to make them about 24% faster. After the study, having lived through it, they still believed AI had sped them up by around 20%. The actual measured result: they were 19% slower with the AI than without it (METR, Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity, July 10, 2025).
Sit with the size of that miss. Not “AI helped a little less than they thought.” They were slower, and they were certain they’d been faster — by roughly forty points in the wrong direction. The researchers called the gap between perception and reality “striking,” and they were careful to flag that the study used early-2025 tools, which keep improving; a later follow-up found different numbers as the models got better. So don’t read this as “AI makes everyone slower forever.” Read it as the thing it actually proves, which doesn’t expire: the tool feels like it’s working even when it isn’t, and your own sense of how well you’re doing is not to be trusted. The output looked finished. It felt fast. The feeling was wrong.
Now ask the obvious follow-up. If experienced developers — people with deep judgment about their own code — can’t feel the difference between speeding up and slowing down, what happens to someone who doesn’t have that judgment? Someone who can’t tell, looking at the output, whether it’s good or just good-looking?
The turn: it returns the quality of the judgment you feed it
That question is the whole thing. The equalizer story assumes the hard part was making the artifact. But producing a thing and knowing whether the thing is right are two completely different skills, and AI only collapsed the first one.
The cost of making a layout, a feature, a draft — that fell to nearly zero. The cost of knowing which version is actually good, and which one is confidently broken — that didn’t move at all. If anything it went up, because now there’s a flood of plausible-looking output to sort through and a tool that will defend any of it with equal confidence. The scarce skill quietly slid from can you produce it to can you tell good from almost-good — and “almost-good” is exactly what these tools are best at manufacturing.
This is why the same machine hands back two different things to two different people. It’s a multiplier sitting on top of whatever judgment you bring. Feed it sharp taste and it executes that taste at speed — you become the person who knew the layout was off-balance, fixed it in one instruction, and shipped by lunch. Feed it nothing — no sense of what good looks like, no eye for the wrong note — and it executes that at speed too. It gives you a confident, finished-looking version of not-knowing. The output is polished. The judgment underneath it is missing, and the polish hides the hole.
A substitute would close the gap. An amplifier widens it. The equalizer was supposed to make your taste irrelevant. Instead it made your taste the only thing that’s left.
A substitute would close the gap: it’d do the discerning for you, so your taste wouldn’t matter. An amplifier widens it: it does more of the producing, which throws all the weight onto the discerning — the one part it can’t do for you. That’s the inversion.
Proof one: the variance is the person, not the prompt
You can watch this directly. Hand the identical model to a room of people with the same prompt and you don’t get the same result — you get a spread, and the spread tracks the operator, not the tool. The person who knows the domain asks the second and third question, catches the wrong assumption in the first answer, redirects, and lands somewhere good. The person who doesn’t takes the first plausible output and ships it.
The tool is a constant in that room. The only thing that changed across the desks is the judgment driving it. Which means the output is mostly a readout of the person — the prompt is just the surface. We’ve gotten used to calling this “prompting skill,” as if the trick is knowing the magic words. It isn’t. Knowing what to ask for is just judgment wearing a keyboard. You can’t prompt your way to an answer you wouldn’t recognize as right if you saw it. The blank box doesn’t add taste. It reflects back exactly how much you brought.
Proof two: it can hand you the answer and quietly take the understanding
Here’s where the sorting gets sharper, and where it turns on the exact people the equalizer story was supposed to rescue: the beginners.
In January 2026, Anthropic ran a controlled trial with 52 mostly-junior software engineers. Half solved coding problems with an AI assistant; half solved them by hand. Afterward, everyone took a comprehension quiz on the work they’d just done. The hand-coding group scored 67%. The AI-assisted group scored 50% — a gap the researchers measured at nearly two letter grades, with the largest difference showing up on debugging, the skill you need precisely to catch when something’s wrong (Anthropic, How AI assistance impacts the formation of coding skills, January 29, 2026). The two groups finished at almost the same speed. One of them just understood far less of what it had made.
Read what that does over time. A beginner leans on the tool to produce the work. The work comes out looking fine, so it feels like learning. But the understanding that’s supposed to accumulate underneath — the thing that becomes judgment after enough reps — doesn’t accumulate, because the tool did the part where the learning lives. The researchers put it plainly: the productivity may come “at the cost of skills necessary to validate AI-written code.” You end up able to generate things you can’t evaluate. You can make it; you can’t tell if it’s right. That’s not the equalizer. That’s the gap opening — between the people whose judgment is compounding because they’re still doing the hard reps, and the people whose judgment is stalling because the tool keeps doing them instead.
One detail in the same study is the whole escape hatch, so hold onto it: the people who used the AI to ask questions and get explanations — who treated it like a tutor — retained far more than the ones who just had it hand over finished code. The tool isn’t the villain. How you use it is the sorting variable. More on that at the end.
Proof three: it doesn’t just fail to help weak judgment — it actively bends it
This is the uncomfortable floor of the whole argument, and it’s the part the equalizer story never accounts for. A neutral tool would, at worst, leave a low-judgment user where they started. AI doesn’t leave them where they started. It pulls them down.
Researchers Lucía Vicente and Helena Matute ran a clean version of this. People did a simple classification task with help from an “AI” that was deliberately set up to be biased in a particular direction. The AI-assisted group, predictably, made more errors than people working unaided — they inherited the tool’s mistakes. Then came the part that should stop you. The researchers took the AI away and had the same people keep doing the task alone. They kept making the AI’s specific errors. The bias stuck after the tool was gone, baked into how they now saw the problem. And this held even though, in one experiment, 80% of participants had noticed the AI was making mistakes (Vicente & Matute, “Humans inherit artificial intelligence biases,” Scientific Reports, 2023).
Sit with that last number. They saw the tool was wrong, and absorbed its wrongness anyway. Noticing wasn’t enough to protect them — the only thing that would have protected them is enough independent judgment to override what the tool nudged them toward, and that’s exactly the thing a low-judgment user is short on. This is the mechanism behind the sorting. AI doesn’t sit politely beside weak judgment. It leans on it, and weak judgment bends. The person without a strong internal sense of “no, that’s wrong” doesn’t just fail to gain from the tool. They quietly take on its errors and carry them out the door — and now they’re worse than if they’d never opened the window.
So line the three findings up. Experienced people can’t feel when the tool is hurting them. Beginners lean on it and the understanding never lands. And anyone short on judgment absorbs the tool’s mistakes and keeps them. Every one of those failures lands hardest on the person with less to start with. That’s not a level field. That’s a machine that takes whatever gap already existed and pulls the two ends apart.
The mirror nobody wanted
If you want one picture for it: AI handed everyone the same mirror.
A mirror is brutally fair. It adds nothing and hides nothing. Stand in front of it with a trained eye and it shows you the thing you can already half-see, sharp enough to fix — that’s most of what taste is, the ability to look at your own work and catch the wrong note before anyone else does. Stand in front of it with no eye, and it shows you nothing you didn’t already see, which is to say nothing. It can’t lend you a perception you don’t have. It can only return the one you brought.
We were promised a ladder — a thing that lifts you up past the people above you, regardless of where you started. We got a mirror.
And the cruelty of a mirror is that it’s most useful to the person who needs it least, and least useful to the person who needs it most. That’s the sorting, in one image. The ladder would have closed the gap. The mirror widens it, person by person, because it gives everyone back exactly what they walked in with — and people did not walk in equal.
So judgment is the asset — which is the one thing it can’t hand you
Here’s the line the whole argument has been walking toward, and it’s the uncomfortable one: the thing AI makes most valuable is the one thing AI can’t give you.
It can give you production for free. It can give you a draft, a layout, a function, a first pass, in seconds. What it can’t give you is the sense of whether any of that is good — the discernment that says this part is wrong, that assumption is off, this is competent but it isn’t right. That has to already be in your head when you sit down, because the tool can only reflect it, not install it. And the way you get it hasn’t changed at all. It’s still the slow part: doing the reps, building the thing and taking it apart to see why it worked, being wrong enough times that you develop a feel for right. The exact work the equalizer story told you that you could finally skip is the work that now decides which side of the sort you land on.
This is the genuinely hard pill, so let me say it straight. The people best positioned in an AI-saturated field are not the ones who got fluent at the tool the fastest. They’re the ones who already did, or are still willing to do, the unglamorous work of building taste — and who use the tool to spend that judgment faster, not to avoid having it. Fluency with the machine is cheap and getting cheaper; everyone will have it within a year. Judgment about what the machine should produce is expensive, slow to build, and compounding — and it’s now the entire difference between two people at identical desks with identical tools.
What to actually do with this
The map correction is the whole point, so here’s where it sends you.
If you’re early — deciding whether it’s even worth learning a craft because “AI does it now” — the lesson is the opposite of the one the hype handed you. It is more worth learning, not less, but learn it for the judgment, not the production. Do the reps by hand long enough to build a real sense of what good looks like, before you let the tool do them for you. Remember the escape hatch in the Anthropic study: the ones who treated the tool as a tutor — asking why, making it explain — kept their understanding; the ones who treated it as a vending machine lost it. Use it to learn faster, never to skip the learning. That single choice is most of the sort.
If you’re already in the field, the move is to stop competing on speed of production — that race is over and the tool won it — and start competing on the quality of the call. Be the person who can look at four confident, finished-looking outputs and say which one is actually right and why. Spend your AI time on more cycles of judgment, not on outsourcing the judgment itself. Notice when the output feels finished, because that feeling is exactly the trap the experienced developers fell into — and check it against something real.
Go back to those two people opening the same window on the same Tuesday. The difference between them was never the machine; they had the same one. It was everything they’d built before they sat down — the eye that could tell, in the polished output, which version was right. The equalizer story said that eye stopped mattering. It’s the only thing that still does. AI didn’t flatten the field. It handed everyone a mirror and started sorting — and the sort runs on the one thing you have to build the slow way, before the tool can give it back to you at speed.
Sources
- 1METR — Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity (July 10, 2025) — randomized controlled trial, 16 experienced developers, 246 tasks; 19% slower with AI while predicting 24% faster and believing 20% faster afterward. Authors note the early-2025 toolset and a later follow-up with different numbers.
- 2Anthropic — How AI assistance impacts the formation of coding skills (January 29, 2026) — randomized controlled trial, 52 mostly-junior engineers; AI group scored 50% vs 67% on a comprehension quiz (≈two letter grades, Cohen’s d=0.738, p=0.01); largest gap on debugging.
- 3Lucía Vicente & Helena Matute — “Humans inherit artificial intelligence biases,” Scientific Reports (Nature portfolio), 2023 — across three experiments, AI-assisted participants made more errors and continued making the AI’s specific errors after the AI was removed; 80% noticed the AI made mistakes yet still inherited its bias.