

You run a small team — a few people, maybe an intern — and the old deal is quietly breaking. The deal was: you assign work, your people do it, you check it, it ships. But every month, the agents do more of the doing. So the honest question isn’t “how do I get my team to use AI.” It’s the one underneath: what should my people actually do all day now?
Here’s the answer, and it’s the whole piece in one line: your team’s job is to train the agent, not do the work. The unit of work has shifted from finish the task to teach a system to finish the task, then check it. Your best person isn’t the one who closes the most tickets anymore — it’s the one whose trained agents close the most tickets while they sleep. That’s a real change in what you hire for, what you reward, and how the week is structured. The rest of this is how to actually run it.
This is for you if you lead or manage a small team — a founder with three reports, a team lead with an intern, a head of a five-person function — and you can feel the ground moving but don’t yet know what to put your people on. If you’re a solo builder, you already live this; you don’t need the management layer. If you run a function big enough to have an “AI transformation” team, this is too small for you. Everyone else: this is aimed straight at you.
The shift, concretely: from doing to teaching
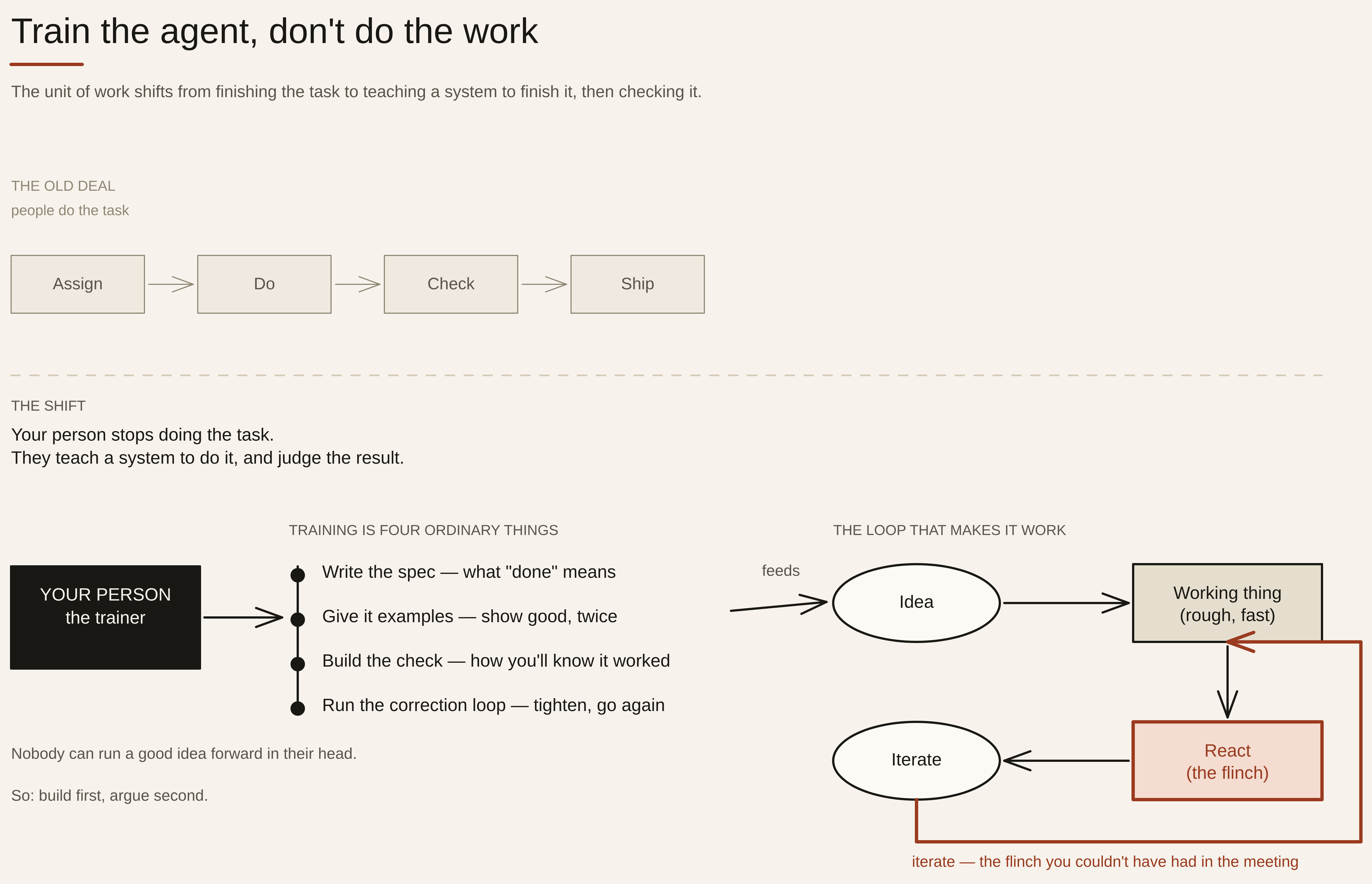
“Train the agent” sounds like a slogan until you make it concrete, so let’s make it concrete. Training an agent is four ordinary things, none of them magic:
- Write the spec. Say, precisely, what “done and correct” looks like — the same thing you’d tell a sharp new hire on day one, except you have to write it down because the agent won’t read your face.
- Give it examples. Show two or three worked cases of the task done right. Models learn the shape of “good here” far faster from examples than from adjectives.
- Build the check. Decide how you’ll know it worked — a test, a rubric, a second pass, a number that has to come out right. This is the part people skip, and it’s the part that matters most.
- Run the correction loop. It gets one wrong, you see why, you tighten the spec or add the missing example, and you go again.
Spec, examples, check, correct. That’s the job. Notice what it is: it’s management. You already do a version of this with people — you brief them, you show them what good looks like, you review, you give feedback. The agent just runs the loop in minutes instead of weeks, and it never gets bored of the correction. So the skill you’re moving your team toward isn’t “prompting.” It’s the thing good managers have always done — define the outcome, judge the result, close the gap — pointed at a system instead of a person.
This isn’t a hunch about where work is going; it’s already the measured shape of it. Anthropic’s Economic Index, which mapped over four million real Claude conversations onto the U.S. Department of Labor’s task database, found AI is used to augment a person’s work 57% of the time and to automate a task outright 43% of the time (arXiv 2503.04761, February 2026). Read that again from a manager’s seat: the dominant mode isn’t the machine replacing the worker — it’s the worker steering the machine. Augmenting is just the gentle name for training and checking. Your team is going to spend its days doing the 57%. Your job is to make them good at it.
Why this is a management shift, not a tools memo
You could read all that and conclude “great, I’ll tell everyone to use the agents more.” That’s the trap. Telling people to use AI more is a tools memo. What’s actually happening is that the work itself is being re-sorted, and the human half is moving toward the part you manage by, not the part you grind through.
Look at the hiring market, which is the most honest signal there is, because it’s people spending money on what they think they’ll need. A Harvard Business School analysis of nearly all U.S. job postings from 2019 through early 2025 found that after ChatGPT launched, postings for routine, automation-prone roles fell about 13%, while demand for more analytical, technical, and creative work rose about 20% (Harvard Business Review, March 2026; corroborated by the New York Fed’s Liberty Street Economics, May 2026). The routine part of the work is being absorbed. The judgment part — deciding what’s worth doing and verifying it got done right — is what’s getting bid up.
That’s the same movement, inside your team, that you can see across the whole economy. The value isn’t drifting toward people who do more tasks faster. It’s drifting toward people who can specify well and judge well — which, conveniently, is what you’ve been calling “good people” all along. So restructuring around “train the agent” isn’t a bet on a tool. It’s getting ahead of where the value already went.
The loop: build the thing, then react to it
Here’s the part that trips up every smart team, and it has nothing to do with AI. When you ask people to train an agent for a job, their first idea of how the agent should work is almost always wrong. Not because they’re not smart — because nobody can run a good idea forward in their head. You can’t sit in a meeting and reason your way to the right workflow. You think you can. You can’t.
This is old, well-tested ground. The whole build-measure-learn loop that Eric Ries put at the center of The Lean Startup exists for exactly this reason: you build the smallest real version, you measure how it actually behaves, and you let reality correct the plan you had in your head. Design researchers say the same thing from the other side — the Interaction Design Foundation’s guidance on testing prototypes is built on the premise that a prototype reveals problems and reactions you simply cannot predict by thinking harder. The abstract plan feels complete in your mind and falls apart the second it meets a real input.
So the loop your team runs is not idea → plan → build. It’s:
idea → working thing → react → iterate.
Get to a rough working version as fast as possible — hours, not the sprint you’d have scoped a year ago — specifically so you have something to react to. The first version’s job is to be wrong in a useful, visible way. You look at what it actually does, you flinch at the part that’s obviously bad, and that flinch is the real design input. You couldn’t have had it in the meeting. This is why the agents change the management math: the cost of getting to “a working thing to react to” has collapsed, so the team that wins is the one that builds first and argues second — not the one with the best whiteboard.
Practically, this means you stop rewarding polished plans and start rewarding fast wrong drafts. When someone brings you a perfect deck for an agent they haven’t built, that’s the failure mode now. Send them to build the ugly version. You’ll both learn more from ten minutes with the broken thing than from an hour defending the plan.
The build-week: the mechanism that installs all of this
Saying “build first, train agents, reward judgment” is still just words on a wall until you give it a container. The container is a build-week: a structured week where the normal work pauses and everyone — not just the engineers — builds a rough working thing with agents, including automating a piece of their own job.
Why a whole week, and why everyone? Because the reframe doesn’t transfer by explanation; it transfers by people feeling the loop in their hands. Picture it concretely: you tell the team that for one week, the goal isn’t to ship the roadmap — it’s for each person to take one annoying, repetitive part of their own role and train an agent to do it. The person who fields scheduling and intake builds an agent that handles the first pass of it. By Friday they’re not just faster — they understand, from the inside, that their job was never “do the task,” it was “own the outcome and judge the result,” and the task part can be trained away. That’s a thing you cannot tell someone into believing. They have to build it.
A note of honesty here: that “automate your own job” picture is the promise of a build-week, not a guarantee, and not every role compresses that cleanly. Some work is judgment all the way down and there’s little to hand off — which is itself useful to discover. The point of the week isn’t that everyone fully automates themselves; it’s that everyone runs the idea → working thing → react loop once, for real, on something they care about, and comes out the other side managing an agent instead of fearing one.
Run it like this:
- Pick real, owned problems. Each person picks something from their own work that’s annoying and repetitive. Owned problems beat assigned ones — the reaction in the loop only fires when the person actually cares whether it’s right.
- Time-box hard to a rough working thing. The deliverable by mid-week is something that runs, not something that’s designed. If it’s still a plan on Wednesday, that’s the signal to stop planning and build the ugly version.
- Demo and react together. Everyone shows the broken thing. The team reacts. The flinches become the next iteration. This is where the loop becomes visible as a team norm, not a private habit.
- Keep what earns its keep. Some agents survive the week and go into the real workflow; most teach a lesson and get thrown away. Both are wins. A thrown-away agent that taught you the loop paid for itself.
The build-week isn’t a one-time offsite. The first one installs the reframe; running one every quarter keeps the team building-first instead of sliding back into planning-first.
How to restructure the team around it
Once the loop is in the team’s hands, the org chart quietly changes shape. You don’t need a reorg memo — you need to change what a “role” means and what you reward.
- A role becomes the ownership of an outcome and the agents that serve it, not a queue of tasks. Instead of “you do the reports,” it’s “you own the reporting outcome — and the agent that drafts it is yours to train, check, and improve.” The person is accountable for the result; the agent is how the result gets produced.
- Use the intern as your fastest test of the new model. An intern hasn’t spent years building an identity around doing the task by hand, so they adopt “train and check” with the least friction — and they show you fast whether your specs and checks are actually teachable to someone new. If a sharp newcomer can train the agent from your spec, your spec is good. If they can’t, that’s on the spec, not them.
- Reward the trained agent, not the heroic grind. The status signal has to move. Publicly value the person whose agent quietly handles a chunk of the work over the person who pulled a long night doing it by hand. What you praise in the demo is what the team optimizes for by next month.
- Make verification a first-class job, not an afterthought. Someone has to own “is the agent’s output actually right.” Name it, value it, and never let it be the thing that gets skipped when the week is busy — because the augment-and-check half is exactly the half the market is now paying for.
What this does not mean
This is a reframe, not a fantasy, so be clear about its edges or you’ll oversell it and get burned.
It does not mean the work does itself. Someone is still accountable for the output — a wrong answer shipped by an agent is your wrong answer. The agents are genuinely capable: Anthropic reports its Claude Opus 4.6 model resolves around 81% of issues on the standardized SWE-bench Verified software benchmark, and cites a partner whose agent autonomously closed 13 issues in a single day (Anthropic, February 2026). That’s real, and it’s also not 100%, and the missing fraction is exactly where your team’s judgment lives. Capable is not the same as trustworthy-unsupervised.
It does not mean taste and judgment stop mattering — they matter more. When anyone can generate a working thing in an hour, the scarce skill is knowing which working thing is worth keeping. That’s the human half, and it doesn’t automate.
And it does not mean fire everyone and keep the agents. The whole point is the opposite: the people are the ones doing the specifying, the checking, and the reacting — the parts that don’t compress. You’re not shrinking the team. You’re changing what the team is for.
The one thing to remember
If you take one move from this: stop measuring your team by the work they finish, and start measuring them by the agents they train and the judgment they bring to checking them. Run a build-week to install the loop, reward the fast wrong draft over the polished plan, and treat idea → working thing → react → iterate as how your team finds good ideas — because nobody, including you, can run a good idea forward in their head. Your job, and theirs, is to train the agent. The work will follow.
Your best person isn’t the one who closes the most tickets anymore — it’s the one whose trained agents close the most tickets while they sleep.
Sources
- 1Anthropic — Introducing the Anthropic Economic Index (February 2026): 57% augmentation / 43% automation across 4M+ Claude conversations mapped to the U.S. Department of Labor O*NET task database. Primary source. Underlying paper: Which Economic Tasks are Performed with AI? (arXiv:2503.04761).
- 2Harvard Business Review — Research: How AI Is Changing the Labor Market (March 2026): HBS analysis of U.S. job postings 2019–early 2025; routine/automation-prone postings down ~13%, analytical/technical/creative demand up ~20% after ChatGPT’s launch. Corroborated by the Federal Reserve Bank of New York’s Liberty Street Economics (May 2026).
- 3Anthropic — Claude Opus 4.6 (February 2026): ~81% on SWE-bench Verified; partner report of an agent autonomously closing 13 issues in one day. Primary source for current agentic-coding capability.
- 4Strategyzer — Don’t Build When You Build-Measure-Learn: summary of Eric Ries’s build-measure-learn loop from The Lean Startup — build the smallest real version and let reality correct the plan.
- 5Interaction Design Foundation — Test Your Prototypes: How to Gather Feedback and Maximize Learning: the design-research basis for “a prototype reveals what you can’t predict by thinking alone.”
Open: the “Blake” build-week anecdote that prompted this piece (including the receptionist who automated her own intake work) is an illustrative scenario, not a sourced public case study — it is presented as an example, and its underlying claim (that non-engineers can now train agents to handle parts of their own role) rests on the Anthropic Economic Index augmentation data above, not on the anecdote.